Following the spreading of applications powered by Machine Learning models, the issues arised on how to engineer their development and deployment. This is particularly problematic when the applications should run under stringent performance requirements and in a complex environment like a cloud infrastructure with diverse hardware resources (CPUs, FPGAs, etc.).
We performed initial work on this issue and proposed an approach that achieved a 3x speedup over the common case, suggesting practices that pave the way for developing more systematic guidelines and tools.
By Alberto Scolari
PhD Student @ Politecnico di Milano, working on reconfigurable computing systems at NECSTLab
Operational-izing ML: system issues
Machine Learning (ML) models are spreading inside companies, as a basis for their business. Nonetheless, applying ML to your business requires theoretical and technical efforts. As willing-to-be system architects, we digged into some engineering issues of ML models. If you think, e. g., about an e-commerce platform, you have to integrate multiple, diverse data sources (e.g., users’ reviews, products database, streams of transactions, social media, images, videos…). Then you do the model’s math (the ML “magic”) to compute the output, deploying everything on a cloud infrastructure and on hardware (FPGA, of course) that you do not own or know well (operationalization). And your application must obey to stringent Quality-of-Service (QoS) requirements like latency, throughput and model density. All this, without established guidelines or tools, as ML is relatively young.
We worked together with Microsoft, whose cloud deploys many users’ models of all sorts. How can we take a generic ML application, analyze its QoS and accelerate it with a more mature, engineered approach than a per-case approach?
The easier way
If you assume most of the computation is in the model itself, you can accelerate the longest steps with state-of-art techniques, and even make your own hardware. Microsoft Brainwave and Google TPU did this, to name a few. This approach works well for Neural Networks, where the computation within the layers is by far the bottleneck.
The harder way: our work on accelerating ML models
But what if there is no single bottleneck? We took a sentiment analysis application as an example, where multiple steps of text processing occupy most of the compute time. This is the case we observed in many production-like models.
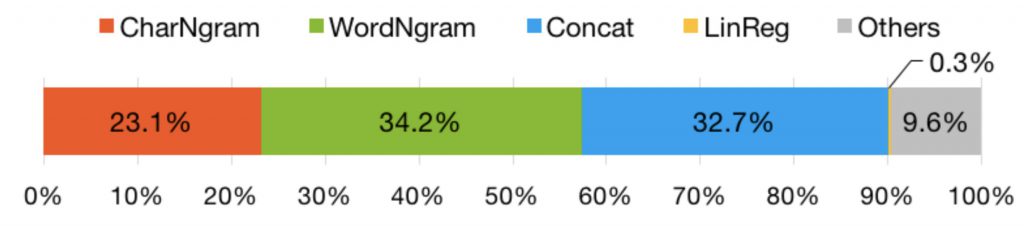
We observed several performance limitations in many applications, which are written in C# with an internal MS tool. These limitations are typical of managed frameworks, whose programming abstractions leave large room for optimization (memory pre-allocation and sharing, code fusions…). Indeed, the first prediction is 540x slower than the second, and many models cannot achieve low latency. Where can we go from here, while remaining generic?
We borrowed the concept of stage from the database world and applied it to our needs: a stage is the unit of computation we run on a device (CPU core, FPGA…), we schedule and we possibly replicate. We fused multiple steps of our ML model into three stages, designed them to share pre-allocated buffers and let the C# runtime work on those tight code units, achieving promising speedups on CPU (87x faster on the first prediction, 3.5x on the following predictions), while the FPGA implementation is limited by memory latency (only 1.5x).
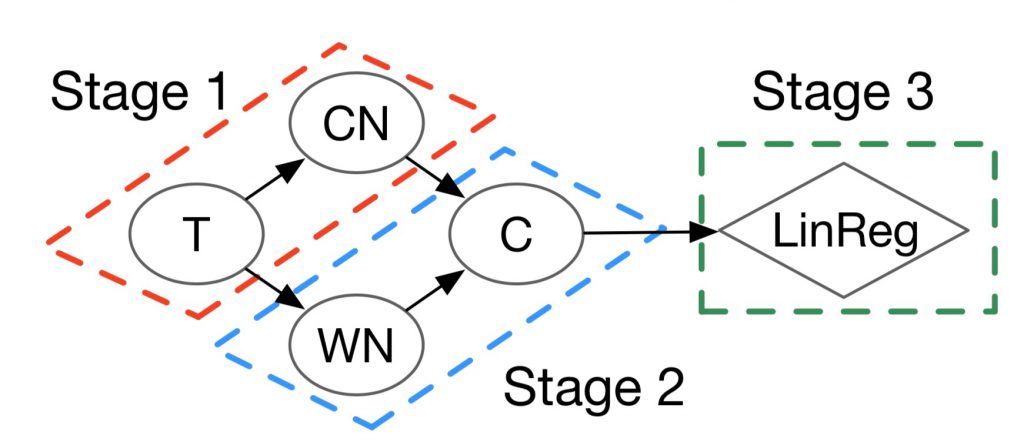
We did this re-design by hand, but we are looking on how to do this automatically for CPU, and possibly FPGA. How to identify stages? How to optimize them automatically? The answers will likely reshape how we operationalize ML at scale.
For more details, you can read the article published at IEEE International Conference on Computer Design (ICCD, Nov 2017)
