Condor is an end-to-end framework to implement Convolutional Neural Networks on FPGA, that does not require the user to have experience in FPGA programming. The framework is able to interpret models from the well-known deep learning engine Caffe.
By Giuseppe Natale
PhD student @Politecnico di Milano
The recent years have seen a rapid diffusion of deep learning algorithms as Convolutional Neural Networks (CNNs) and, as a consequence, an intensification of industrial and academic research focused on optimizing their implementation. Different computing architectures have been explored and, among all of them, Field Programmable Gate Arrays (FPGAs) seem to be a very attractive choice, since they can deliver sustained performances with high power efficiency, as CNNs can be directly mapped onto hardware and still offer flexibility thanks to their programmability.
Nevertheless, the process of designing and deploying FPGA-based hardware accelerators is still a hard and complex task that requires expertise in FPGA programming and knowledge of hardware design tools.
We therefore present CONDOR, an end-to-end framework that is fully integrated with the industry standard Caffe, and therefore allows to use Caffe models as input, completely avoiding the hassle of FPGA programming. This framework is also integrated with the Amazon AWS F1 instances and is therefore able to deploy the resulting CNN in the cloud.
Proposed automation framework
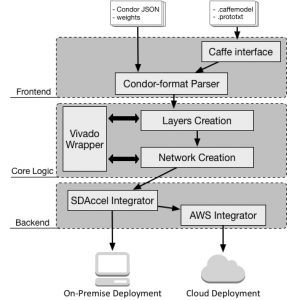
CONDOR has a multi-tier architecture consisting of three layers: the frontend, the core logic, and the backend.
The main goal of the top tier, the frontend, is to collect all the necessary input in order to allow the design of the accelerator. There are currently two supported methods: the user can either specify all the input files manually, according to the CONDOR internal specification, or use a pretrained Caffe model, providing the caffemodel and prototxt files.
The core-logic tier uses the input provided by the frontend in order to create the hardware accelerator according to our methodology and is tailored to the selected deployment option. The intermediate result of this tier is a fully packaged Vivado IP.
As for the backend, we have decided to integrate the CONDOR framework with SDAccel, which is a software development environment targeting FPGA platforms that enables a CPU/GPU-like development experience. With this integration it is possible to deploy the resulting accelerator on-premise, or in the cloud using the Amazon F1 instances.
Hardware Design
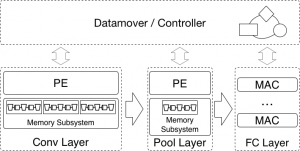
The accelerator is a high-level pipeline which is a composition of building blocks sets with different functionalities: Processing Elements (PEs), implementing the actual computation performed by the different CNN layers, filters, feeding the PEs and implement on-chip buffering for the features extraction layers using a buffering technique known as non-uniform memory partitioning (i.e. where the storage buffers are non-uniform and tailored to the read pattern), and FIFOs, used as storage buffers to perform the non-uniform memory partitioning together with the filters. We interface our accelerator with the on-board memory using a custom datamover which exchanges data with the accelerator using streaming connections.
