This work presents different methodologies to create Hardware Libraries for FPGAs. This allows data scientists and software developers to use such devices transparently from Matlab, Python and R applications, running on Desktop or Embedded systems.
By Luca Stornaiuolo
PhD student @Politecnico di Milano
In the last years, the huge amount of available data leads data scientists to look for increasingly powerful systems to process them. Within this context, Field Programmable Gate Arrays (FPGAs) are a promising solution to improve the performance of the system while keeping low the energy consumption. Nevertheless, exploiting FPGAs is very challenging due to the high level of expertise required to program them. A lot of High Level Synthesis tools have been produced to help programmers during the flow of acceleration of their algorithms through the hardware architecture. However, these tools often use languages considered low level from the point of view of data scientists and are still too difficult to use for software developers. This complexity limits FPGAs usage in a number of fields, from Data Science to Signal Processing. One way to overcome this problem is to realize Hardware Libraries of widely used algorithms that transparently offload the computation to the FPGA device from higher level languages, commonly used by data scientists. This work presents different methodologies to create Hardware Libraries for Desktop and Embedded systems. We have chosen to focus on R, MATLAB and Python languages.
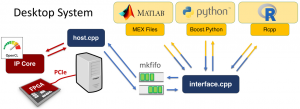
For what concerns Desktop systems, the hardware libraries are developed exploiting the OpenCL paradigm and the Xilinx SDAccel tool. This allows to send and receive data from the
host system to the FPGA through a PCI-Express connection. We have implemented and tested an optimized hardware implementation of the Autocorrelation Function on a Xilinx VC707 board and we reached a speedup of 7x with respect to the execution on an Intel i7-4710HQ.
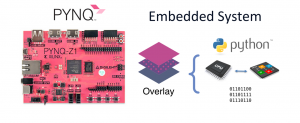
For Embedded systems, we have used the recently released Xilinx PYNQ platform to create Hardware Libraries. We have implemented different optimized versions of some NumPy library functions for the PYNQ-Z1 Board, that supports the PYNQ platform. We are able to achieve a speedup of 3.5x for the Integer Matrices Dot Product algorithm implementation and a speedup of 20x for the Cross Correlation function, compared to the pure software execution.
