When it comes to interpreting streams of data using modern artificial intelligence techniques, such as audio in speech recognition, computational requirements of state-of- the-art models can easily skyrocket and result in huge power requirements. However, accepting a small loss in their accuracy can go a long way in reducing their resource impact. This work explores the boundary between accuracy and performances in such a context.
By Alessandro Pappalardo
PhD student @Politecnico di Milano
Modern artificial intelligence approaches to problems such as image captioning, i.e. describing content of
an image, can already have significant computational requirements. On top of that, scaling such techniques
from processing a single data point, e.g. an image, to a sequence of them, e.g. a video, increases their
requirements non-linearly. The reason is that interpreting a sequence requires not only to interpret each
data point separately, but also to incorporate their context. Continuing with the example of images vs
videos, describing what happens in a video doesn’t simply boil down to describing each single frame
separately, since information from multiple frames needs to be aggregated in order to come up with a
coherent description.
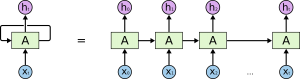
An unrolled RNN.
Recurrent Neural Networks (RNNs) are a class of state-of- the art artificial intelligence models well suited for performing such context-aware sequence processing. In particular, LSTMs (Long Short Term Memory) are a type of recurrent neural networks capable of aggregating information between data points that may lie at a considerable distance between each other. The computational requirements of RNNs in general, and LSTMs in particular, can easily go through the roof. A paper from Google Cloud on their first-gen TPU (Tensor Processing Unit) reported RNNs and LSTMs as taking round 30% of the workload generated by AI applications deployed internally on their infrastructure.
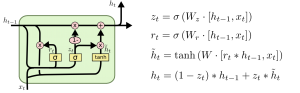
An LSTM neuron.
What typically is done in these cases to try to alleviate this computational burden is to reduce the precision
of the involved operations, i.e. go from the usual 32 bits per operand down to 8 bits, which usually guarantees the same accuracy as the full-precision model, and can result in reduced computational requirements on general-purpose architectures. However, there is no reason why an amount of bits less
than 8 couldn’t give the same (or a reasonably reduced) accuracy.
The only limit consists in the fact that obtaining computational savings with operands smaller than 8 bits on platforms such as CPUs or GPUs tend to be hard. However, the same limitations do not apply to FPGAs, whose granularity at the bit level is much finer. The work I developed during my internship at Xilinx Research in Dublin, in collaboration with University of Kaiserslautern, takes a close look at what can be achieved in terms of computational savings when it comes to accelerating extremely quantized LSTMs on FPGAs. As s first proof-of- concept task to accelerate, we picked OCR of a picture of a single line of text, in which the sequence of data points consists in a sequence of columns of pixels. Our results shows that the computational requirements of LSTMs for OCR can be reduced up to 8x on FPGAs by means of extremely reduced precision, with only a negligible loss in accuracy, giving new reasons on why FPGAs should be a platform of choice for artificial intelligence acceleration in data centers.
